
Decisions, Decisions
Published:
Hi!!
It’s been a little while since I’ve written one of these; something I’m trying to do this sumemr is get back into writing more. In Florence, as I was writing my art history papers I knew what I was writing was straight garbage; all writing has a shelf life, a period of time it takes before you read it again and want to Thanos-snap it away. While I was going on and on about cOnvEXitY in Michelangelo’s work, I realized it had been years since I’d written anything with a decent shelf life that was longer than a tweet. It’s something I used to do a lot more, and the process was always challenging and exciting even if the end result wasn’t quite what I wanted it to be. Most of what I usually write is in response to some new change in my life: a new job, a new quarter, or a new perspective, but I wanted to mix it up this time around!
I’m going to be talking about machine learning today :(
This is a project I worked on in the fall, that seems like a cool idea in principle and actually worked quite well! I don’t think I’m gunning for a PhD so publication in a conference isn’t really that high of a priority; I think it’s a simple idea that can work well in practice, provide one uses it thoughtfully. More crucially, I think it’s a way to practice technical writing and explaining ideas that people kind of instantly recoil at in layman’s terms, and to even try and make it fun. These are important ideas that are already shaping decisions in governments and corporations.
In particular, this project (which we called Deep-LASSO), deals with the issue of interpretability, which sounds simple but is actually a difficult concept to pin down. In this, I’ll try to keep a lot of the mathy details to a minimum, but also go into asides about important related topics in the field and what I think their implications in the larger world are.
Motivations
Deep learning? I’ll pass.
Whether its from the news or the memes, you’ve probably heard a lot about deep learning and neural networks, and how they’re gonna take over and usher in a new age that necessitates UBI, massive worker re-education, and a fundamental change in how we view work in our society. Despite all the type, in reality most companies use much older technology.
This is kind of hard to believe, given all the hype surrounding AI startups. Kind of unsurprisingly, companies greatly exaggerate their use of AI, and in many cases any use of statistics/data at all is considered machine learning. Even this seemingly low, low bar is not even met by a lot of startups: one study showed that 50% of AI startups in the UK had no AI tech at all. A couple of jokes about startups having nothing but getting funding:
“We just secured $25m in funding!” “What do y’all have so far?” “Oh, just some powerpoint slides.” Two months later “Our valuation just fell tenfold.” “Why?” “We actually started writing code.”
Who’s the most important person in the early stage of a startup? The VP. Not vice president, but the video producer.
There are a couple of reasons why we don’t see nearly as many neural networks/deep learning methods in production as you would think:
These models have huge computational costs associated with them, and few applications truly need the firepower that these larger models provide.
These models are considered black boxes, which means the outputs of the model are not interpretable. This is especially true for tabular data (think taking a spreadsheet and trying to predict a housing price, rather than trying not to hit pedestrians given a video feed for a self driving car or a chatbot trying to seduce your SSN out of you.)
Lots of time, simpler stuff works just as fine, and providing fast service is more important. At a tech talk at TwoSigma, which has some of the smartest people in the world for them, the quants said that after joining the company they learned more about linear regression than they ever thought they would learn, and in practice most companies end up using a simple, linear model, because interpretability and performance are ultimately more important to your long-term bottom line then tricking a couple of VCs who don’t know any better. There exist some ways for making neural networks more interpretable, but a lot of times the results of these methods are shaky at best (e.g., class activation maps for computer vision), work well empirically but don’t really do what you think they do (attention, in one of the papers that made me pretty fucking sad. It’s such a great idea and it should work! And it works! Just not in the way we all thought it would.), or are super fucking slow (Shapley values. Might be the only thing that works under GDPR, and works for any kind of model, but O(2^n) runtime? Boy bye).
But what if we could make neural networks more interpretable? On tabular data, neural networks aren’t all that slow and vastly outperform linear models.
The importance of interpretability
I’ll hit this harder in the post-mortem, but interpretability is becoming of greater concern to companies using machine learning to power their services. Interpretability is a hard (perhaps impossible) thing to define too rigorously, but a good intuition is this:
Interpretability is the degree to which a human can understand the cause of a decision.
Seems simple enough! When a decision is interpretable, we can better understand the context in which it is made, we can better understand the strengths and weaknesses of the model, and more importantly we can start to try and solve some of the potentially problematic behaviors these models can exhibit. There have been a lot of headlines in the news about algorithms displaying racist and sexist behaviors; if we can’t understand why a model might be making a decision, it’s harder to reason about what might be wrong with it and we might just leave it at that, and not try to debug it; after all, it’s this machine learning thing I’ve been hearing all this fuss about.
So, we have our core motivation: let’s find a way to make a deep neural network operating on tabular data interpretable.
Tired: Vanilla LASSO. Wired: Deep LASSO
Lasso is a great idea that’s been around for a while. Also called L1 regularization, it’s a way to make a linear regression model even more interpretable! The interpretability of linear regression comes from its weights: you know how much each feature contributes to the output. L1 makes this better by enforcing sparsity, or by encouraging the model to have as most of its weights as zero; humans can’t reason in more than three dimensions, so limiting the number of things you have to look at, since you only have to look at nonzero weights, makes things easier for a human to understand. Lasso provides two main advantages: sparsity and regularization (limiting the space a model can learn, so that you’re more likely to generalize to unseen data).
We propose Deep Lasso! Most neural networks work like this: you have a bunch of numbers, you toss in a bunch of values, and it spits out a single number. For example, a model intended to predict housing prices might take in median income in the neighborhood, square foot size, number of bedrooms, and a whole bunch of other features and then spit out a number. In Deep Lasso, instead of spitting out a single number and having that be our answer, we spit out a vector, with the same dimension as the input. We then take the dot product of the input with this vector, which gives us a scalar, which is our magic number. Here’s a picture.
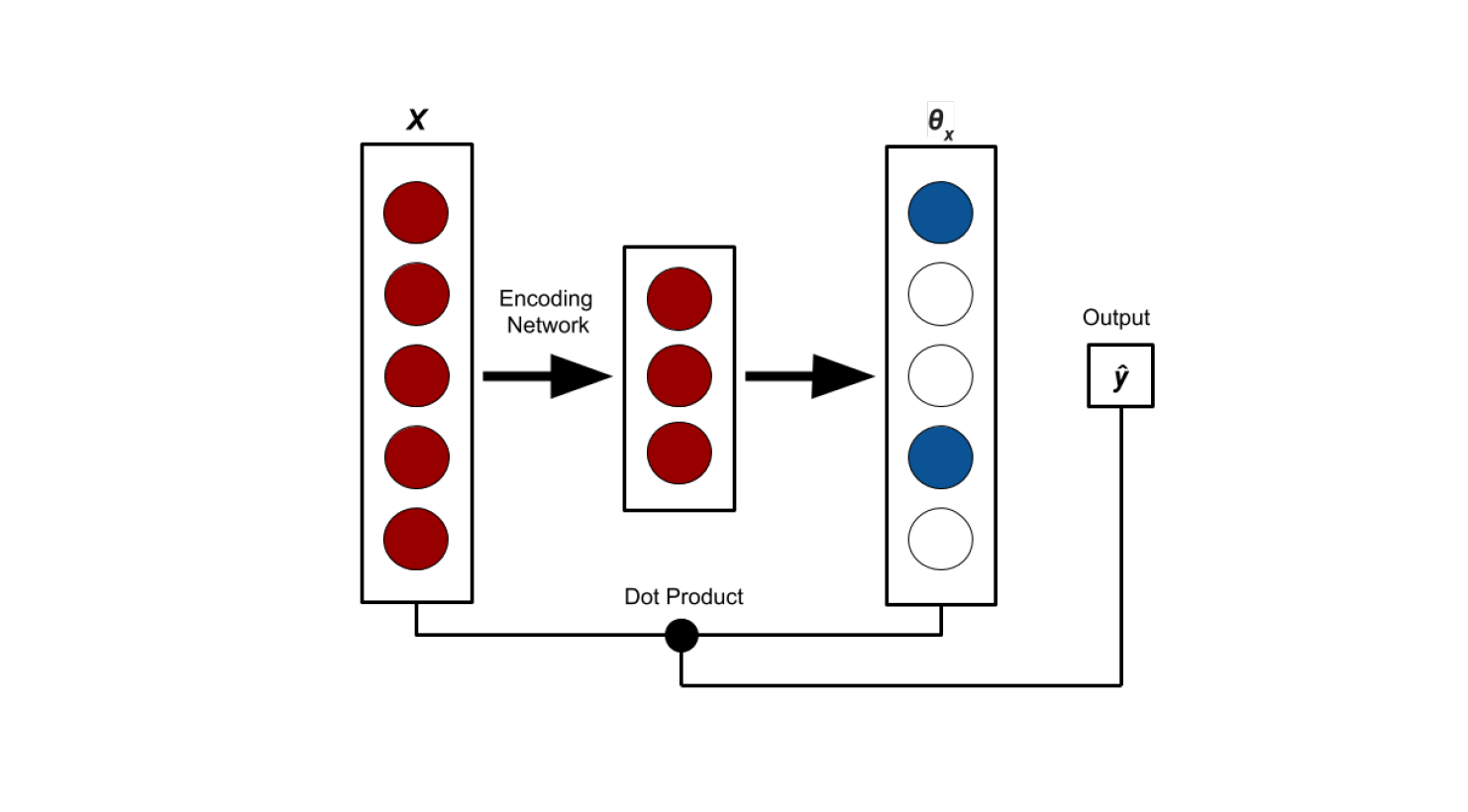
This seems like a pretty roundabout way to ultimately arrive at the magic number, right? The cool thing is, the vector produced by the Deep Lasso model provides the exact same kind of interpretability as a linear model; for a given input, you know the weights applied to each feature when you calculate the output, something not provided by a normal neural network. In the fashion of LASSO, we apply an L1 penalty to the weight vector produced: we want it to be as sparse as possible. There are a couple of distinct advantages this method provides:
The model’s explanation (the weight vector produced) can be different given different inputs! This is pretty key; for a linear model, the explanation for every input is the same, and doesn’t take into account interactions that might happen between the features. This gives our model example level interpretability, where linear regression models have global interpretability. If those words are scary, I’ll explain them in more detail in the post-mortem.
This framework is super fucking general; the input data and encoder model don’t matter. All that matters is that you have some kind of vectorized input, and that you have a model that will spit out a vector of the same size, that you use to interpolate the features of the input. You can use tabular data (which we focus on because of lack of methods and wider use), but you can also use an image as the input and a convolution neural network to generate the vector.
You can generate counterfactuals! You can change a feature value and view the change in explanation and output. That is, you can ask the model “If I do this instead of that, how does the decision and your explanation for the decision change?”
Empirically, this method works! It destroys linear models in performance while providing explanations that on a surface level are at least as good as those provided by linear models. Without the L1 penalty, it performs just as well as a normal neural network, and with regularization it generalizes better and has sparsity, albeit not to the extent that we would like. We’ll discuss this later.
What kinda went wrong?
Heh. Sparsity is hard. Like really hard. I even looked up some dumb shit called a SEL0 penalty which is an approximation of the L0 penalty (which is even more stringent on sparsity than L1, but is nondifferentiable) and that just fucking broke the model. When the weights aren’t sparse, if you have like 50 features to look at it is a clusterfuck to look at. Also it was super hard to tune the L1 penalty hyperparameter and it felt a little finicky. BatchNorm/LayerNorm helped a bunch!! Sparsity is an increasing area of interest! OpenAI came out with a paper on sparse transformers, which are based on attention and thus a lil like this, and they made some batshit crazy claims about generating sequences thirty times longer than blah blah state of the art blah. I haven’t read the paper but I’ve seen a lot of renewed interest in sparsity so hopefully this issue can be fleshed out!
Why does it work? Why might it not actually work?
There are a couple of interesting ways you can think about why this method works, and analogues with solid theoretical foundations (this stuff is more mathy mathy bleh):
Local linearity! If you go back to your AP calculus days, remember the concept of local linearity: that if you zoom in enough, functions are locally linear. Here, we effectively are building a local linear regression explanation for a decision at a specific input. This is analogous to ideas like a Taylor polynomial, or to LIME (a technique devleoped by Percy Liang where you train a simple, interpretable model around an input point you’re interested to reason about its local behavior.)
Generative models: You can also think about this as mapping between two vector spaces: some input space and some kind of explanation space, like a generative model.
Attention. Depending on how you feel about that attention paper, this is a good or a bad thing! The idea, at a very high level, is very similar: you take a weighted sum of your input features, where the weights are a function of your input.
One interesting thought experiment/failure case is multiplication. Imagine you have a feature vector with two features, x and y. Your output label is the product of the two features. Now hypothetically a neural network can approximate any function (if you really want to get confused, try to reason/google about how a neural network can ever learn multiplication. This is why I drink), so DeepLasso would be able to learn this, but if you didn’t know that the output label is just xy, would the explanation provided by DeepLasso reflect the actual nature of the function? It seems as if there’s a disconnect between the expressivity of the model and the expressivity of its explanation (which we will talk about in much greater detail!)
At the moment, we can agree that Deep Lasso, at least in principle, generates a sparse, locally linear explanation for a given decision while being able to learn non-linear functions! This is cool! This is useful, and it was very exciting to work on. A paper did a similar thing to explain AlphaGo, but not in the same manner, not with sparsity, and didn’t think to generalize the approach, so suck it
Is interpretability just actually hopeless?
First, let’s talk about global and local/example interpretability. Global interpretability is about understanding how a model makes decisions on all data, where local interpretability centers around a decision
Oof. A survey of current methods in ML interpretability basically boils down to “good luck ever getting global interpretability.” Essentially, humans are dumb and can’t really interpret sophisticated models (at least for how models are built today). Thus, we need to have a simple model to make it explainable to us. So, for global interpretability, this boils down to getting a simple model to approximate what your complicated, powerful, expressive, ripped-as-shit model does on all its data. If a simple model could do that and be interpretable… just use a simple model that’s less likely to freak out whenever it sees something it’s never seen before.
If you kind of accept that, the criticism of DeepLasso in the multiplication thought experiment becomes a lot more tolerable; you’re just getting a local explanation, and it’s practically impossible to capture your global behavior on data without knowing your underlying distribution; and if you already know your underlying data distribution, why are you trying to learn a model to approximate it? Any reasonably intelligent model is going to treat different exaples differently based on the quirks of an individual data point, which makes aggregating those differences in treatment impossible. This is like that old saying how the answer to pretty much any question is “it depends.” Can we, as dumb humans, even explain ourselves?
So global interpretability is fucked, but what about local interpretability? If you believe in local linearity, which is the assumption that the model will behave similarly on inputs that are similar to each other, then our model, and most models for local interpretability make sense. I think it’s safe to say that there’s a complicated decision making system in our head that takes into account a ton of features subconsciously, and when we try to rationalize our decisions we usually just pick out a couple of reasons, and as we’ve talked about before its kind of either simplistic or futile to condense our decision making process for a whole class of tasks into a single simple framework; in that way, DeepLasso is kind of not that far off from human decisions! This isn’t an excuse for not having better interpretability methods, but may help us understand why we have trouble coing up with anything too different what our methods for local interpretability: if the goal is to make these decisions understandable to a human, we make the method of interpretability analogous to what humans do, which is inherently flawed.
Furthermore, in what situations are you likely to need to explain a decision? I think there are two main ones: weird failure cases/explain when something is behaving strangely, meaning a data point kind of differently distributed from most of your data, and explaining most of your data. I think in the latter case, you model is more likely to behave in a sensible manner, since these models are designed to do well on most of your data. I think local interpretability is super useful for debugging the first kind of data point, allowing you to iterate and understand why you’re getting weird behavior.
Last note!
No matter what, these methods don’t work if your data is trash. Features that are too correlated to each other? Model becomes garbage cause you don’t know which feature to give more importance. Powerful methods and better ways of interpreting decisions do not remove the need for being careful with what you use to train a model!!!
Wrap-up
Oof!!! Lots of words. Hopefully it wasn’t too much of a slog. I still think machine learning is cool, but I think like most people I’m less bullish on it the longer I work in it; a lot of the advancements are what you call “impressive but not surprising.” People have figured out to do cool things, but usually it’s a small incremental change or throwing a ton of compute power on a task. Interpretability is still important, and researchers/practitioners should try to make their models inherently interpretable in their designs, rather than trying to shoehorn an explanation after the fact, but we should understand the inherent limitations in the information/signal lost in trying to distill a sophisticated decision-making process into a understandable explanation.
Interpretability is a fun thing to think about! There a lot of issues with confirmation bias (what would it take for you to accept an explanation from a model that doesn’t align with your own rationale for how decisions are carried out?), ethics, bias in training, and viability in production. Regardless, as long as corporations can be blamed for their models’ decisions and suffer financial consequences (which should absolutely be the case), interpretability will continue to be a hot area of research! I think we should sacrifice some level of performance in order to have more interpretability, but if the claims of OpenAI and this shit are true, then it’s really not much of a sacrifice.
I have many thanks to give out! Michael Ko was a great help in working on the project, and this whole thing was Anand Avati’s brainchild. Thanks to Robin, Ben, Joe, and Alex for putting a lot of these talking points in my head! Thanks to Robin, Veronica, Jia, Katie and others for writing so pretty and indirectly convincing me to start doing this stuff again!
I think I’ll keep things more narrative/personal based in the future! I’ll bring back the “things I’ve consumed” section. If you want my experimental writeup and stuff (the “paper”), reach out!
If you’re interested in interpretability, here are some great resources:
Distill - This stuff is phenomenal! Really interactive articles Interpretability - Amazing online textbook/webpage on the stuff I’m too lazy to find links. Zach Lipton wrote a really good review paper on the subject. Generalized additive models were also a large inspiration for Deep Lasso (interpolating splines + link func) A KDD Paper called like… G2AM? lou-kdd13.pdf it’s somewhere on the web lol TreeSHAP! You can do Shapley values specifically for tree ensembles in polynomial rather than exponential time.